History
- We had WordNet, which contains synonym sets and hypernyms (“is a” relationship)
- Problem: Missing nuance, missing new meaning of words, impossible to keep up-to-date, subjective
- We had discrete representation, where each word is a one-hot vector
- Problem: Cannot calculate word similarity
- Word vectors: dense vector, chosen such that it is similar to the vector of words that appear in similar contexts
Representing words by their context
- When a word w appears in a text, its context is the set of words that appear nearby (within a fixed-size window)
- Idea: Use many contexts of w to build up a representation of w
Word2Vec
- Continuous Bag of Words (CBOW): look a the words before and after the word to create embedding
- Skipgram: Instead of guessing a word by its context, we guess the neighboring words based on the current word
How to use skipgram
- We can calculate how “likely” the surrounding words based on the current word.
- The objective function is the negative log likelihood.
- We still need to calculate , where we use two vectors per word w:
- when is the center word
- when is the context word
- Then, for a center word c and a context word o (it is similar to softmax!):
Skipgram w/ negative sampling
- Change the task from predicting the neighboring words (which is a softmax problem) into checking if two words are neighbors (which is a binary classification problem)
- We use logistic regression, which is simpler and much faster to calculate
- We need to introduce negative samples into the dataset — randomly sampled from the vocabulary
- Maximize probability of real outside word appears, minimize hte probability that random words appear aroun the center words ( are random words)
- Hyperparameter: window size (default = 5), and number of negative samples (5-20, but usually also 5).
Problems with Word2Vec / GloVe
- OOV
- Morphology: for words with the same radicals such as “eat” and “eaten”, they don’t share the same parameter Solution: FastText → make embeddings of subwords (n-grams) instead, and then we sum everything up
Evaluation of word vectors
Intrinsic evaluation
- Make sure that the word vector analogies make sense
- Take cosim of the word vector and check if they make sense
Extrinsic evaluation
- Use neural networks

- Note that the window size is fixed at a certain number.
Language Modelling
- A language model takes a list of words and attempt to predicts the word that follows them
Perplexity
- This is equal to the exponential of cross-entropy lost
N-grams language model
Problems & Solutions
- Unknown sequence (sparsity) → smoothing and backoff
- Storage (increase n or increase corpus increases model size)
Neural language model
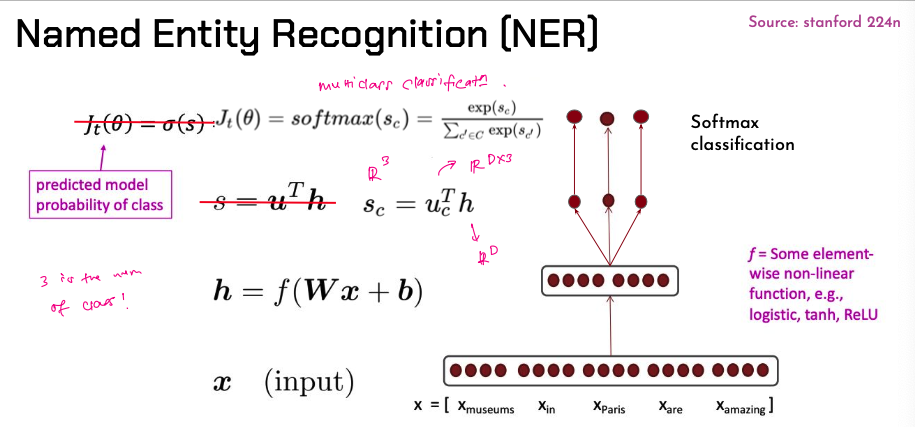
- Similar to NER, but instead of predicting the class of the center word, we want to predict the next word
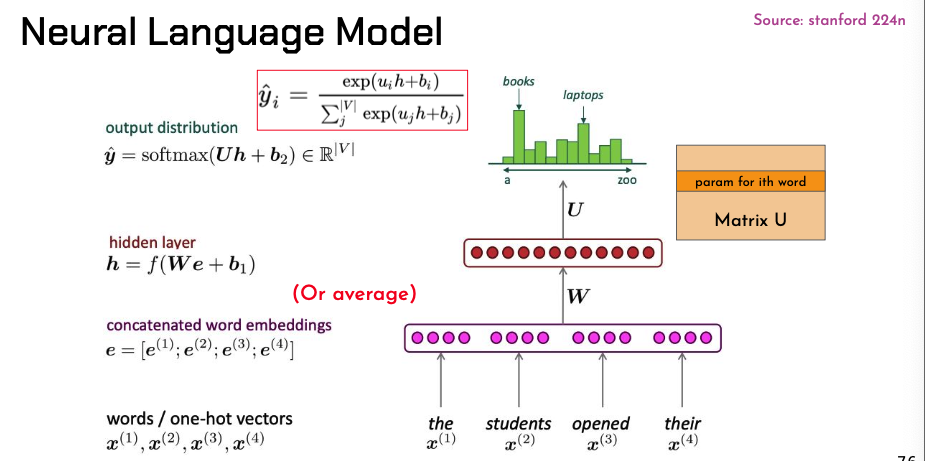
- With this, we don’t have sparsity problem anymore, and we don’t have to store all n-grams Problems:
- Fixed window size
- Enlarging window enlarges
- Window can never be large enough
- and are multiplied by different weights in → no symmetry